Redleaf Engine Update
I’ve always been struck by the fact that while our computers can store files, they don’t really understand them. That’s the idea behind Redleaf—and I’m excited to announce that version 2.0 is now ready.
For anyone new to the project, Redleaf is a local-first knowledge engine. The goal is to take a folder of documents (PDFs, transcripts, HTML, etc.) and turn it into a private, interconnected knowledge graph that you actually own and control.
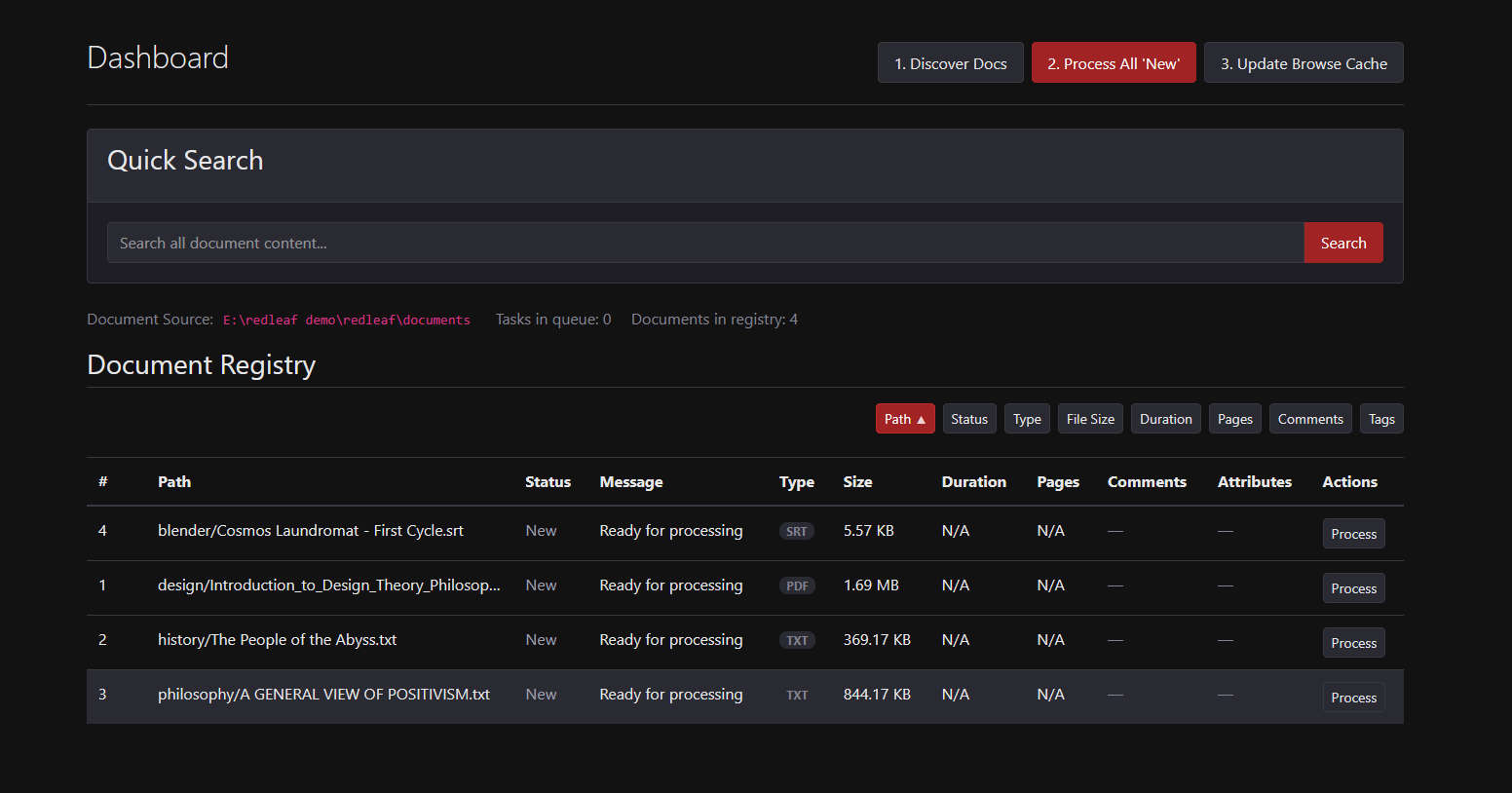
The main dashboard view in Redleaf.
This new version is a big step up in stability and usability. Here are some of the main things I’ve been working on.
Better Document Intelligence
Redleaf 1.0 already used spaCy to extract people, places, and organizations. In 2.0, browsing that information is much faster. On the side of every document there is now an integrated indexing tab showing every detected person, place, and thing—making it much easier to navigate documents at a glance.
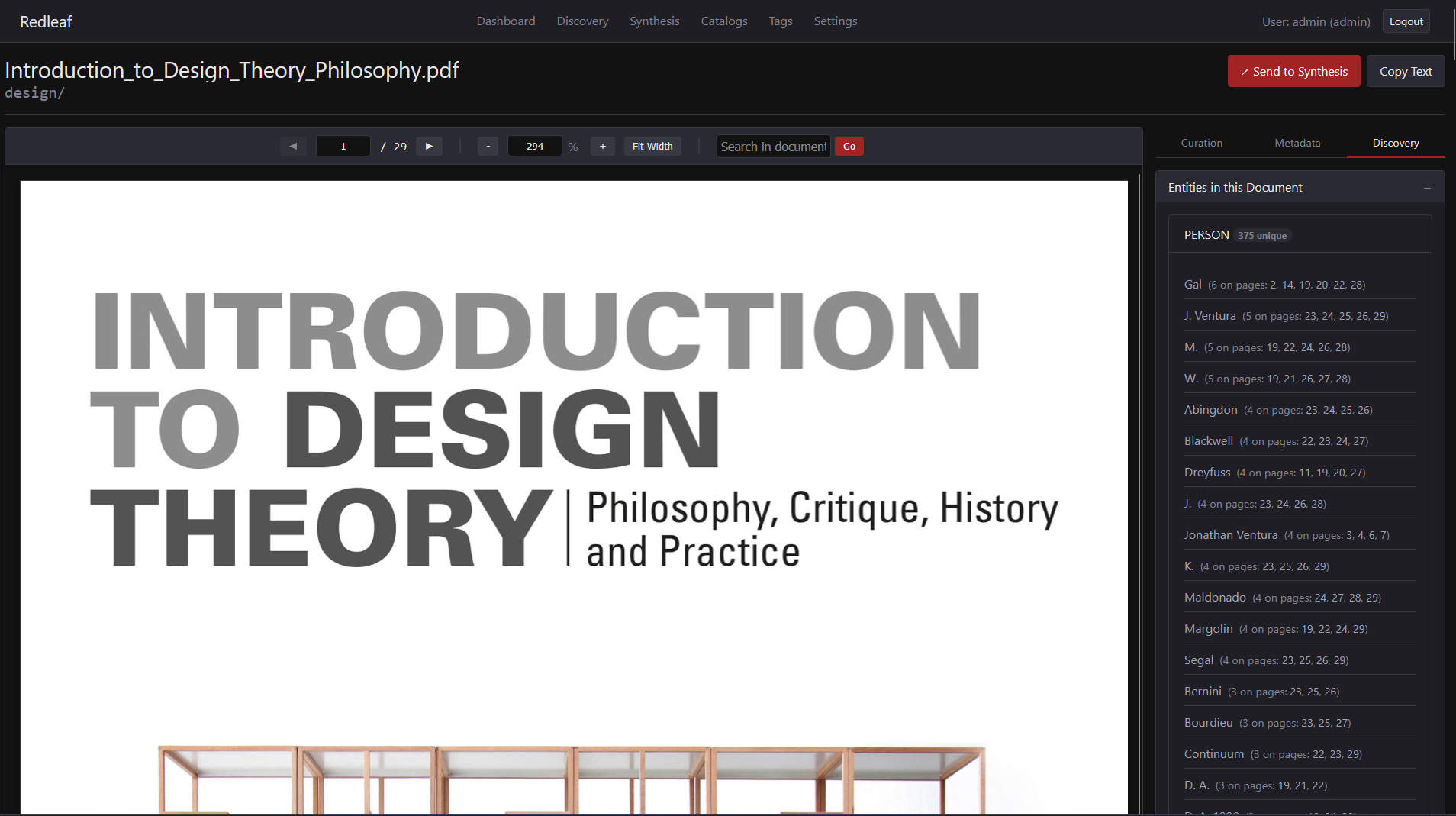
The side panel showing extracted entities.
Implied Relationships
Beyond just listing entities, the engine now analyzes their proximity and context to automatically suggest implied relationships. This helps uncover connections you might have missed.
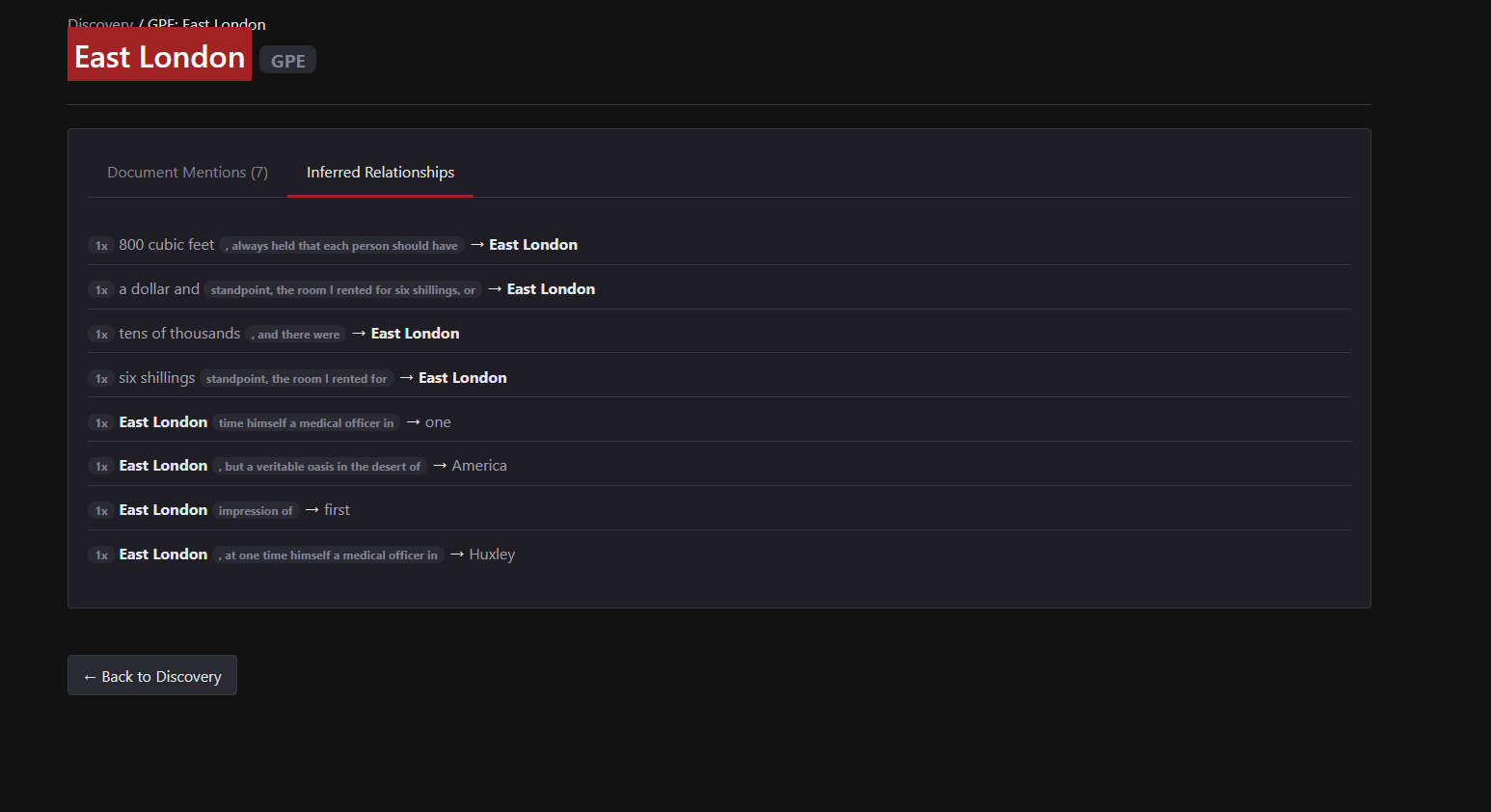
Automatically detecting relationships between detected elements.
A More Practical Writing Setup
The new dual-pane editor is designed for actually getting work done. It has citation tools built-in that generate Chicago-style citations and export to .odt without messing up the formatting.
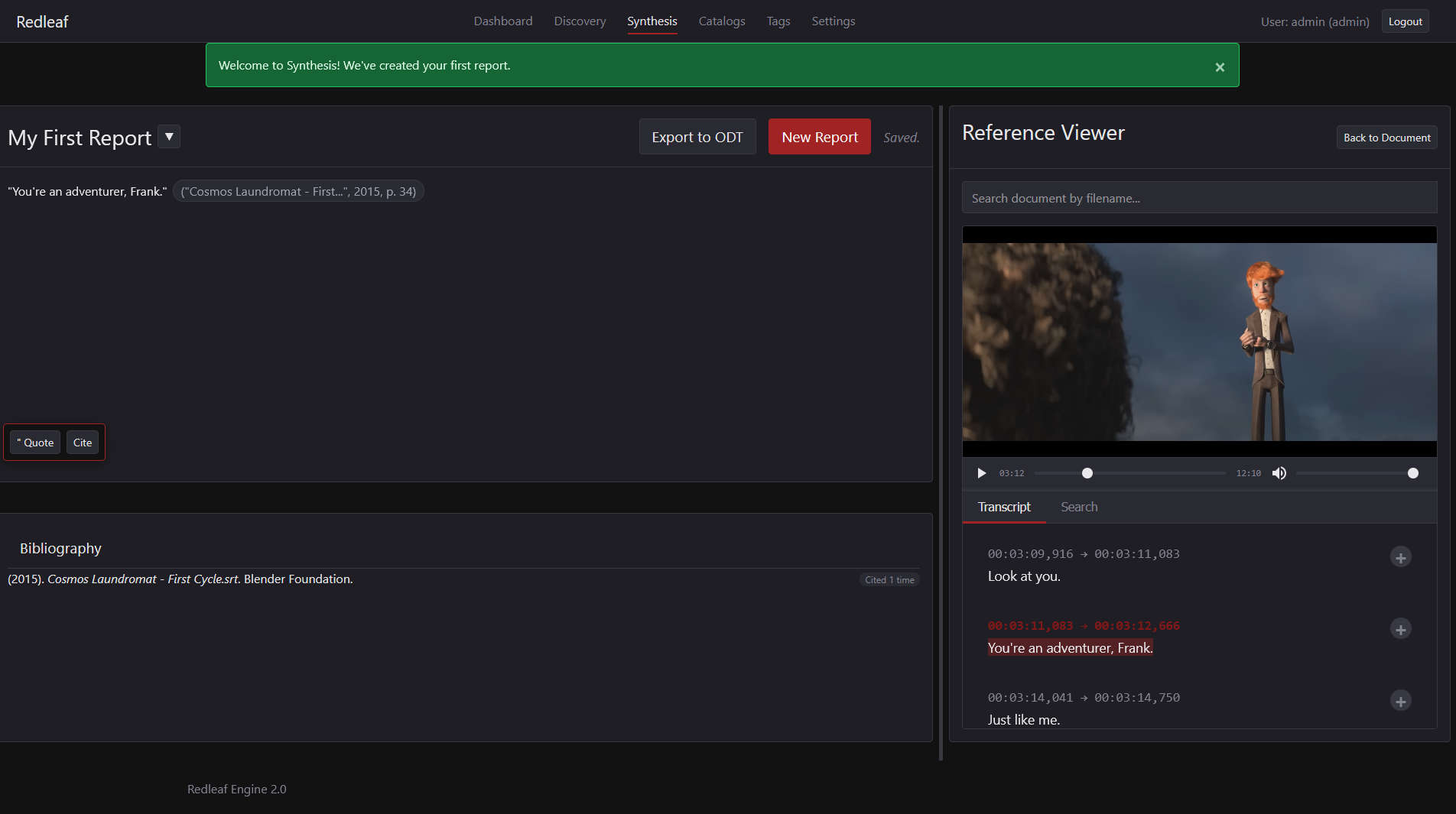
The dual-pane write-up editor.
Interactive Media Viewer
I put a lot of work into the media tools. You can now pair .srt files with podcast .xml feeds to get all the metadata, and the SRT viewer now syncs the audio/video with an animated transcript. The PDF viewer has also been overhauled for a smoother experience.
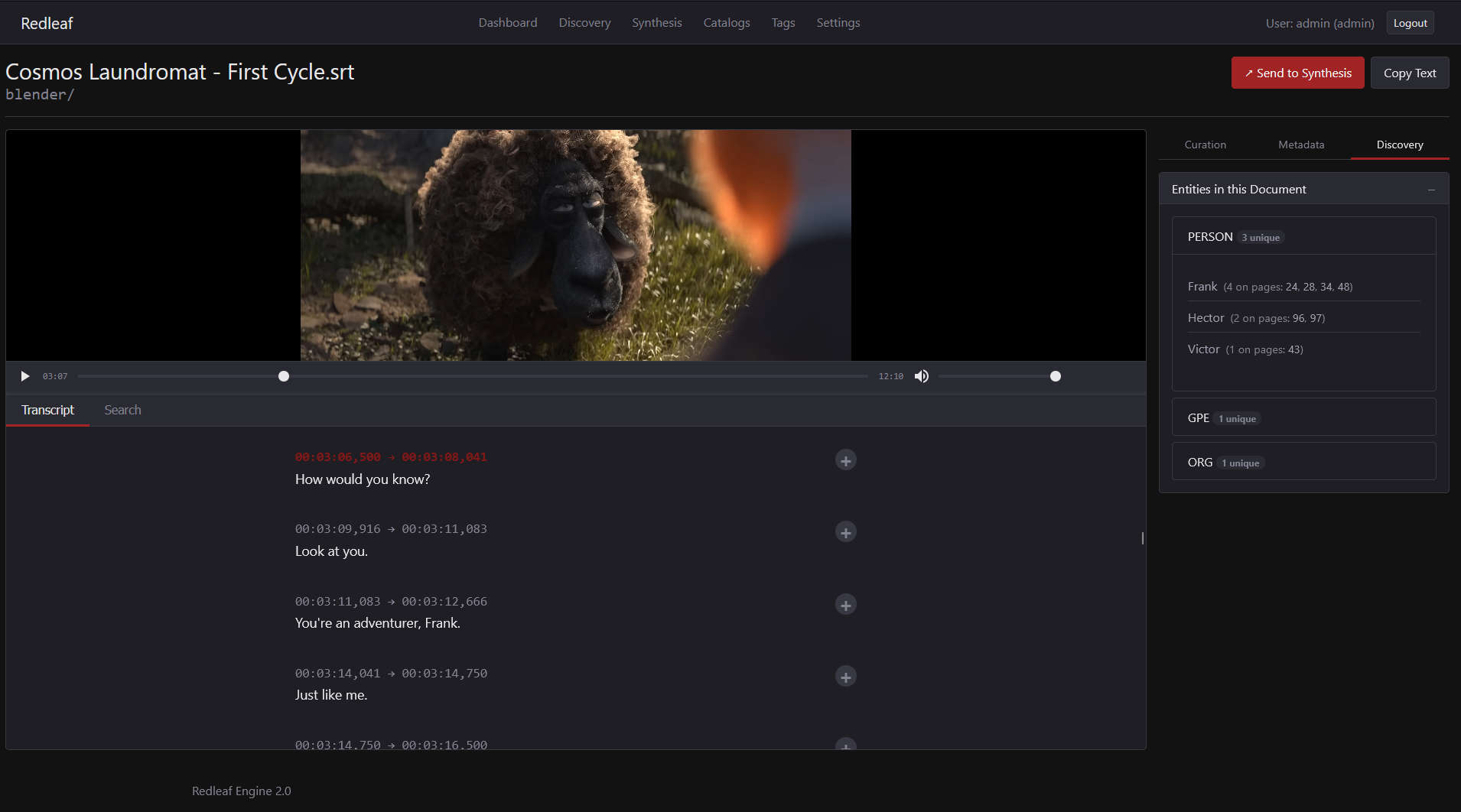
The interactive SRT viewer in action.
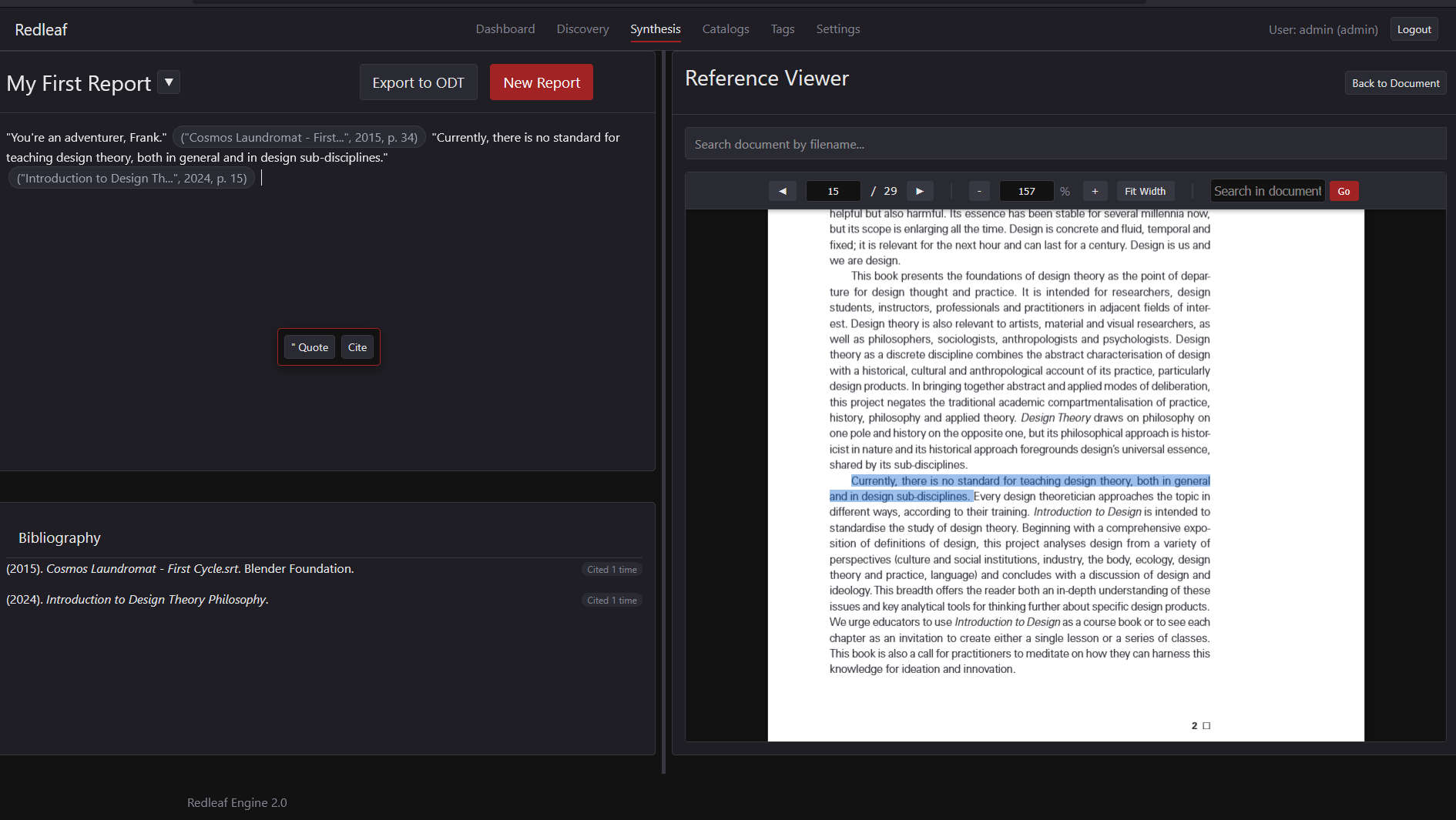
A PDF loaded up in Synthetist to cite.
Portable Knowledge Graphs
You can now export an entire graph as a single .rklf file. A teammate can import it, point it to their copy of the source documents, and the whole graph links back up without any reprocessing.
Under the Hood
I also spent a lot of time on stability. I redesigned the multiprocessing core to make it more robust, and the PDF viewer got an overhaul with in-document search, which makes it much nicer to use.
What’s Next on the Roadmap
I’m already planning the next steps for the engine. Here are two of the big ideas I’m exploring:
- Optimized PDF Experience: Rather than just loading a standard PDF, I’m working on a process that ingests and converts PDFs into an optimized internal format. The goal is a much faster and more integrated experience, similar to how sites like Archive.org handle documents.
- Local Email Indexing: I want to add the ability to ingest exported emails (like
.mboxfiles). This would allow you to build a searchable, interconnected graph of your email history without having to keep it all on a cloud server.
Redleaf Engine 2.0 is ready. I’d love for you to try it, break it, and let me know what you think.
— Nathaniel Westveer